Ship bug-free applications. Let AI do the full QA. Start for free.
Accessibility, Performance, Security, API, Mobile, Real-device, Visual regression, Stress testing — 36 test types in one platform, with AI on top.
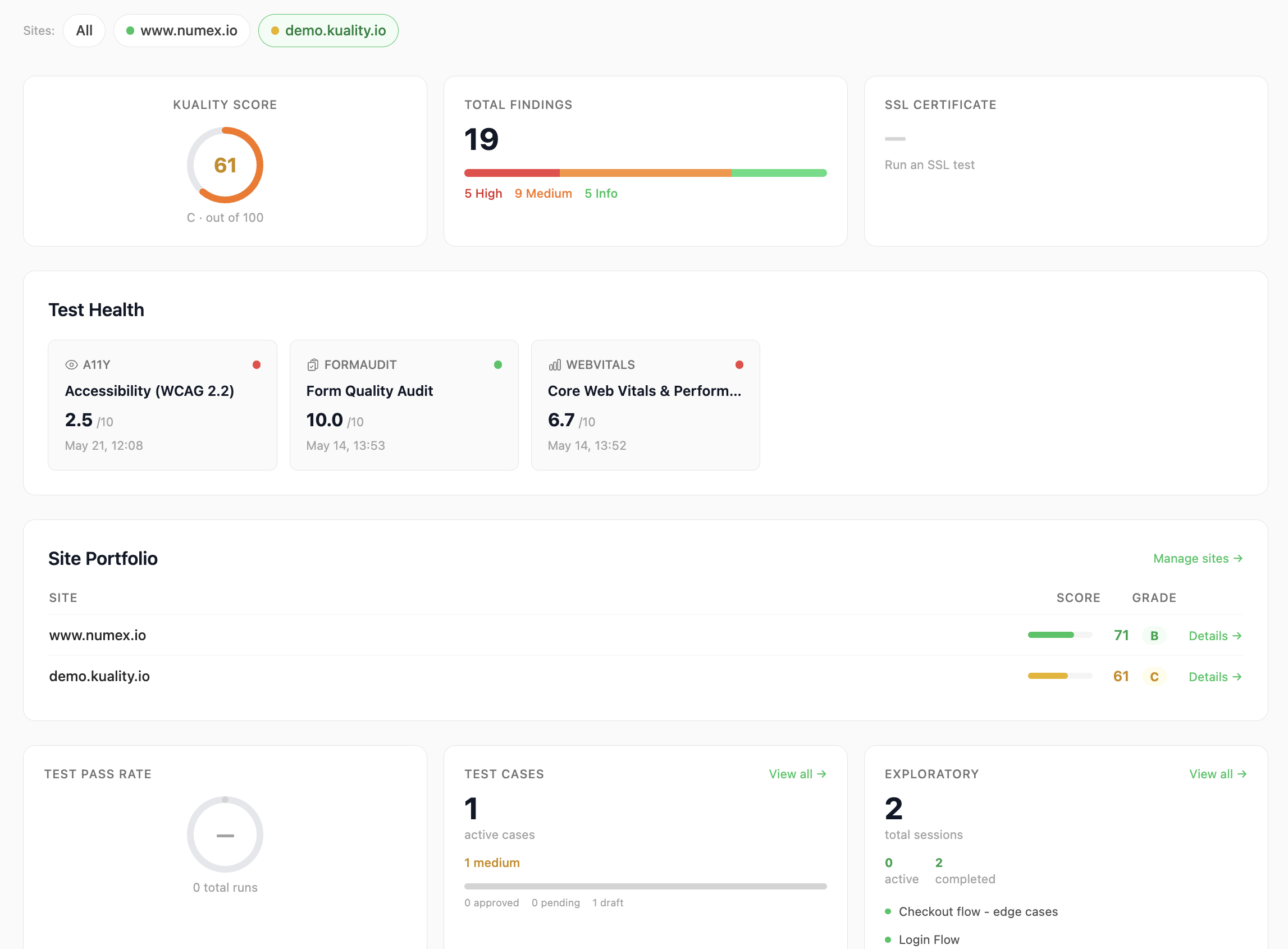
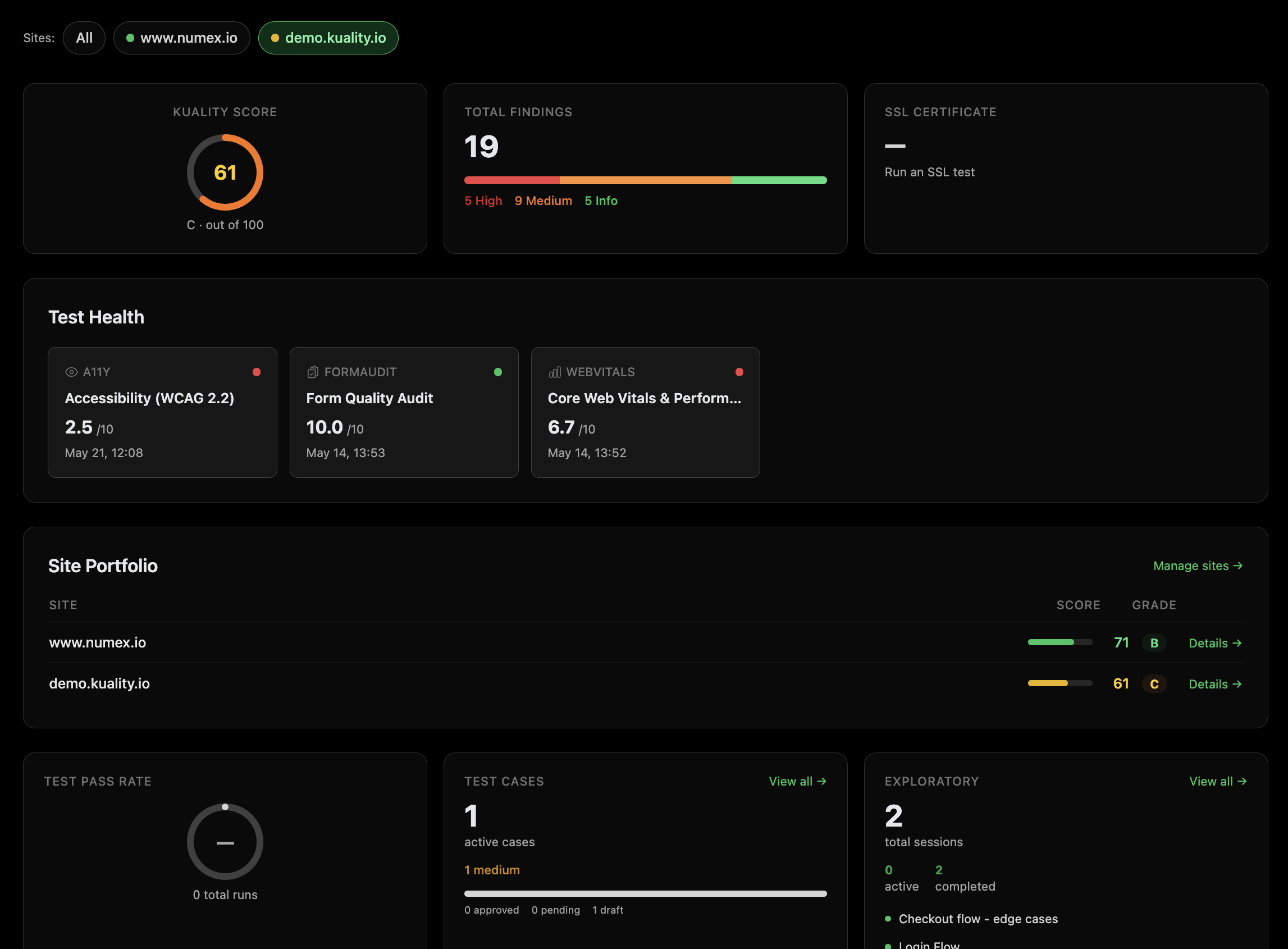
One number per application. Track it over time.
Every test feeds a single weighted score from 0 to 100, graded A+ through F. Watch it trend across deploys, compare staging vs. production, share it on a public status page, and put it in front of execs as a one-page PDF.
Skip the test plan. Let the AI run QA for you.
Paste a URL — even one behind a login. Pick the test families you care about. Kuality AI plans the run, drives a real browser, exercises your app, and hands you back a severity-graded report with screenshots, DOM snippets, and one-click Jira / Linear tickets. No setup. Full scripts when you need them. No QA backlog.
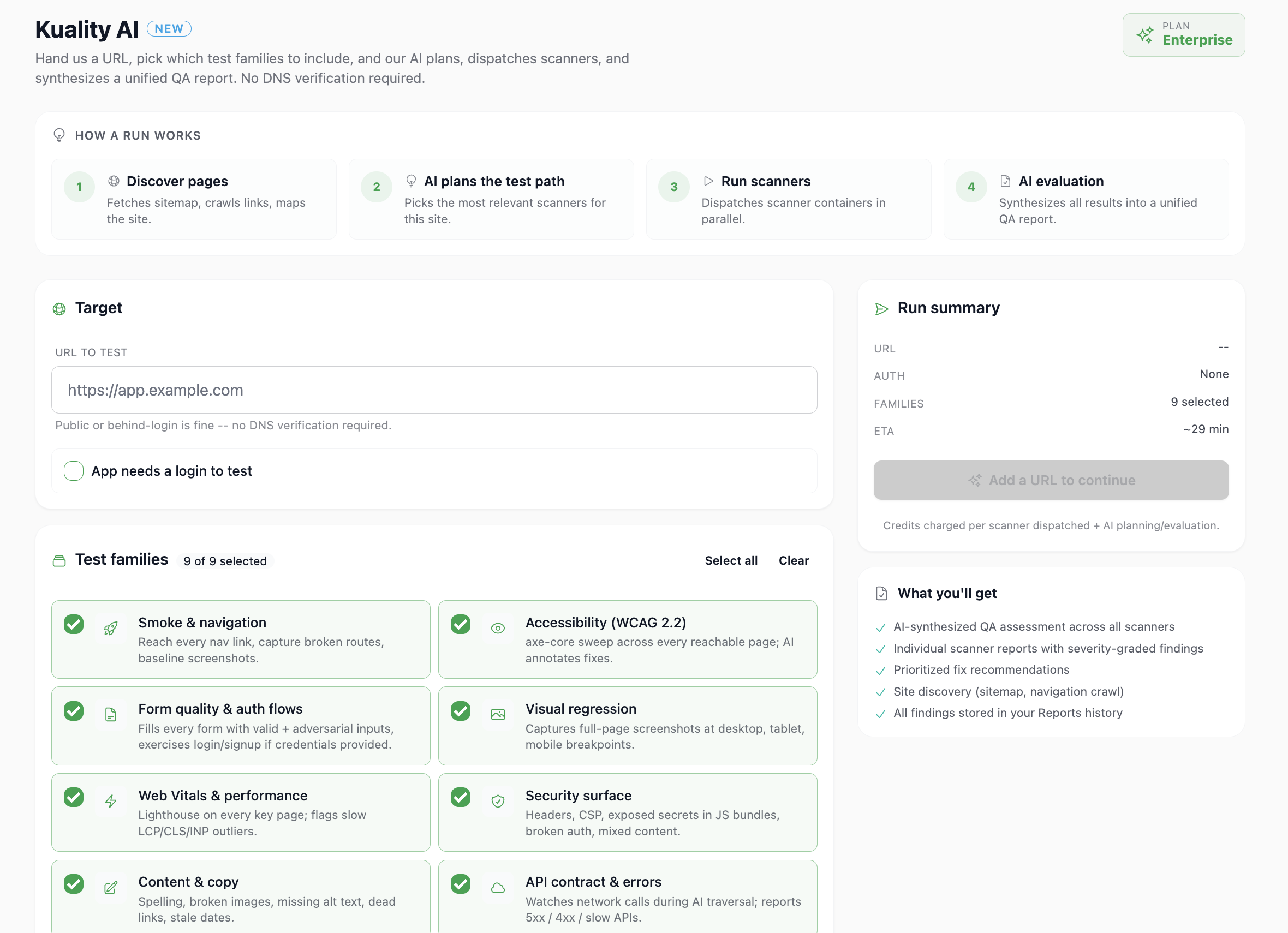
Four steps. Zero test scripts.
Every run generates full Playwright scripts you can export, customize, and rerun.
-
STEP 1Paste a URL
Public or behind-login. Drop in credentials and we drive a real browser session.
-
STEP 2Pick families
Accessibility, performance, security, visual, mobile, API contract — check the boxes that matter for this release.
-
STEP 3AI plans + drives
The agent explores your app, exercises flows, captures DOM + screenshots, and prioritizes findings by business impact.
-
STEP 4Get the report
Severity-graded findings with reproducible step traces, one-click Jira / Linear tickets, and a shareable PDF.
Everything your QA team needs.
Not just tests. The workflow, the integrations, and the reports that make QA a part of shipping — not a bottleneck.
Find your ceiling before production does.
Ramp real traffic from verified domains and watch RPS, p95 latency, and error rate in real-time. Distributed across regions, with multi-location simulation. See exactly when — and where — your stack breaks.
- DNS-verified target ownership
- Custom ramp profiles & load shapes
- Waterfall breakdown by endpoint
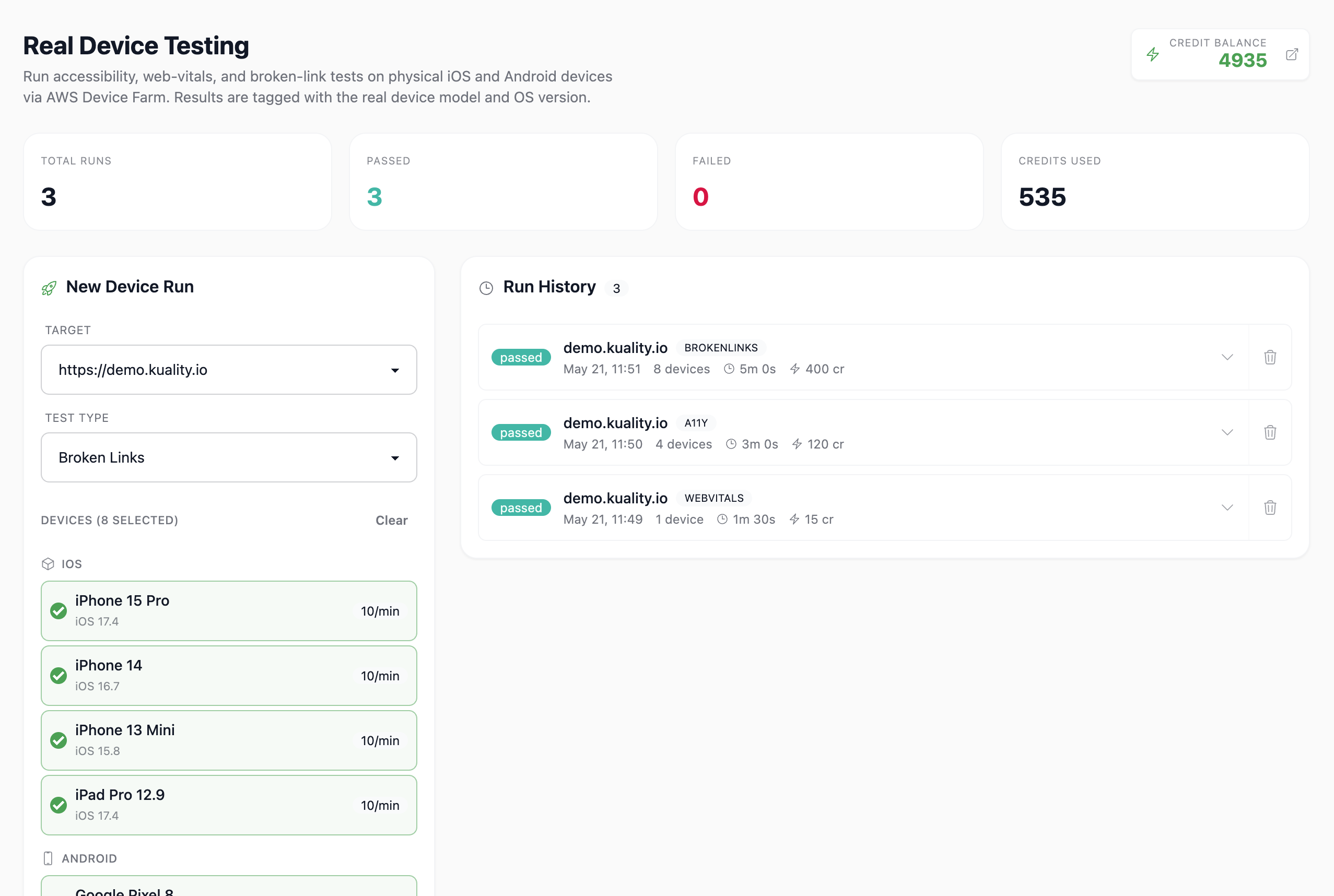
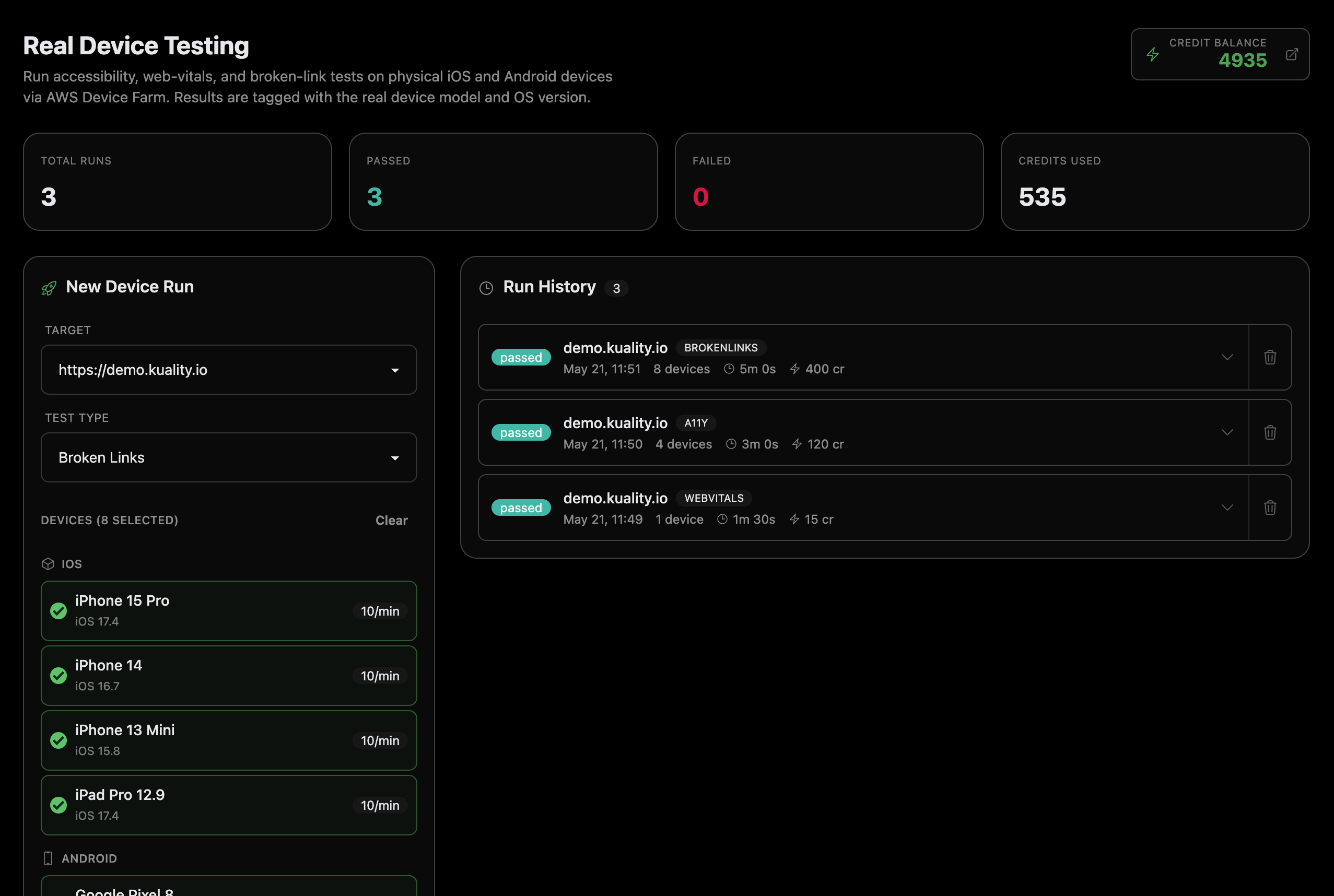
Real Mobile Devices. No device lab.
Run accessibility, Web Vitals, and broken-link tests on physical iPhone and Android handsets in our real-device farm — no BrowserStack account, no hardware to own. Pay per device-minute via credits, and surface the bugs headless browsers miss: safe-area clipping, system font overrides, OS-level dark mode.
- iOS 15/16/17+, Android 12/13/14+, major device models
- Device matrix testing — pass/fail grid across configs in parallel
- AI device matrix advisor — minimal config set for your audience
Pixel-diff every PR. Catch the broken hover state.
Every test captures page screenshots across breakpoints. We diff them against your last known-good build and surface the delta — right down to a 2px shift in a footer link. QA doesn't catch "I didn't know that button moved" after production.
- Desktop, tablet, mobile breakpoints
- Ignore-regions for dynamic content
- Approve/reject directly from a PR comment
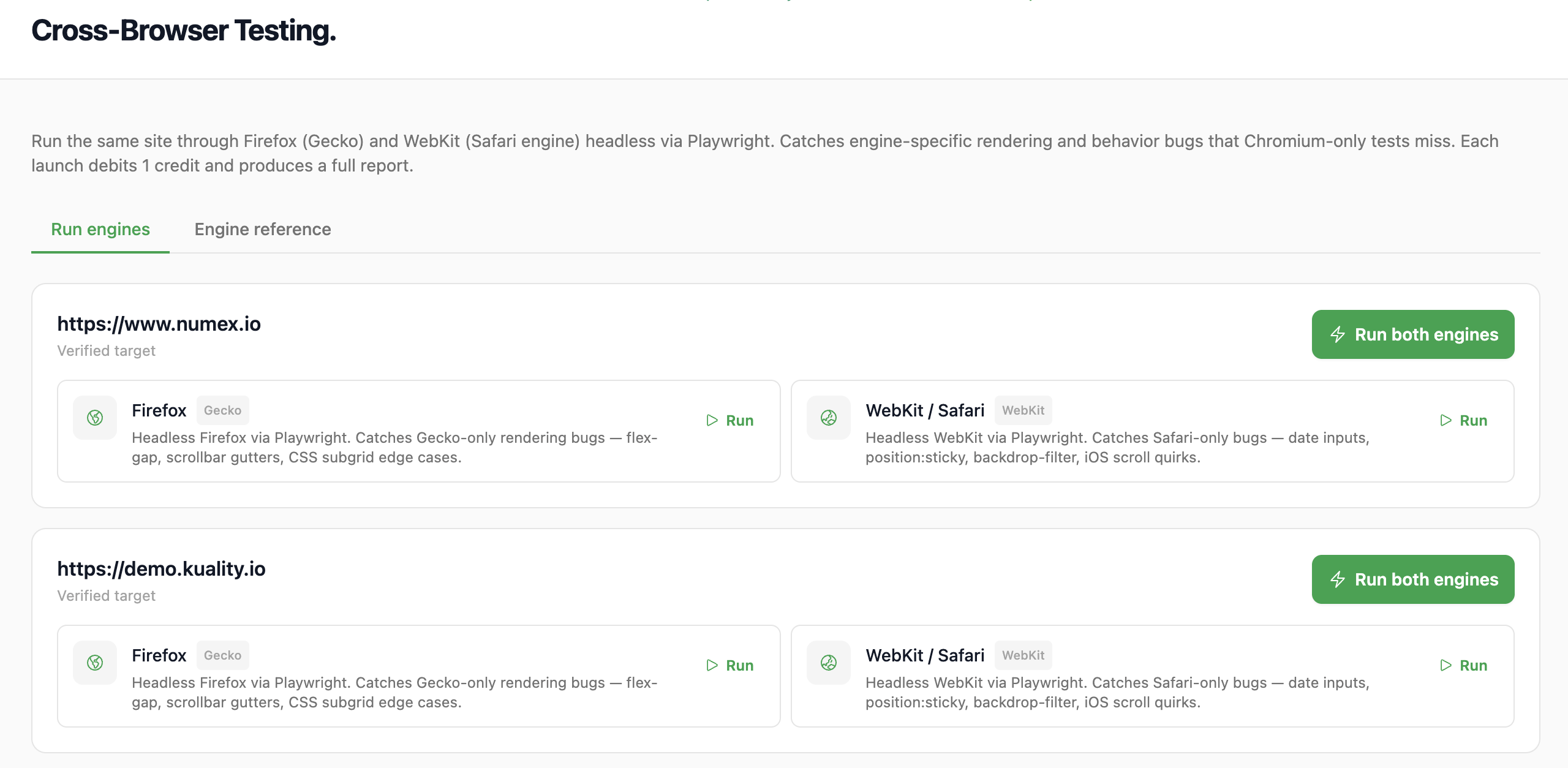
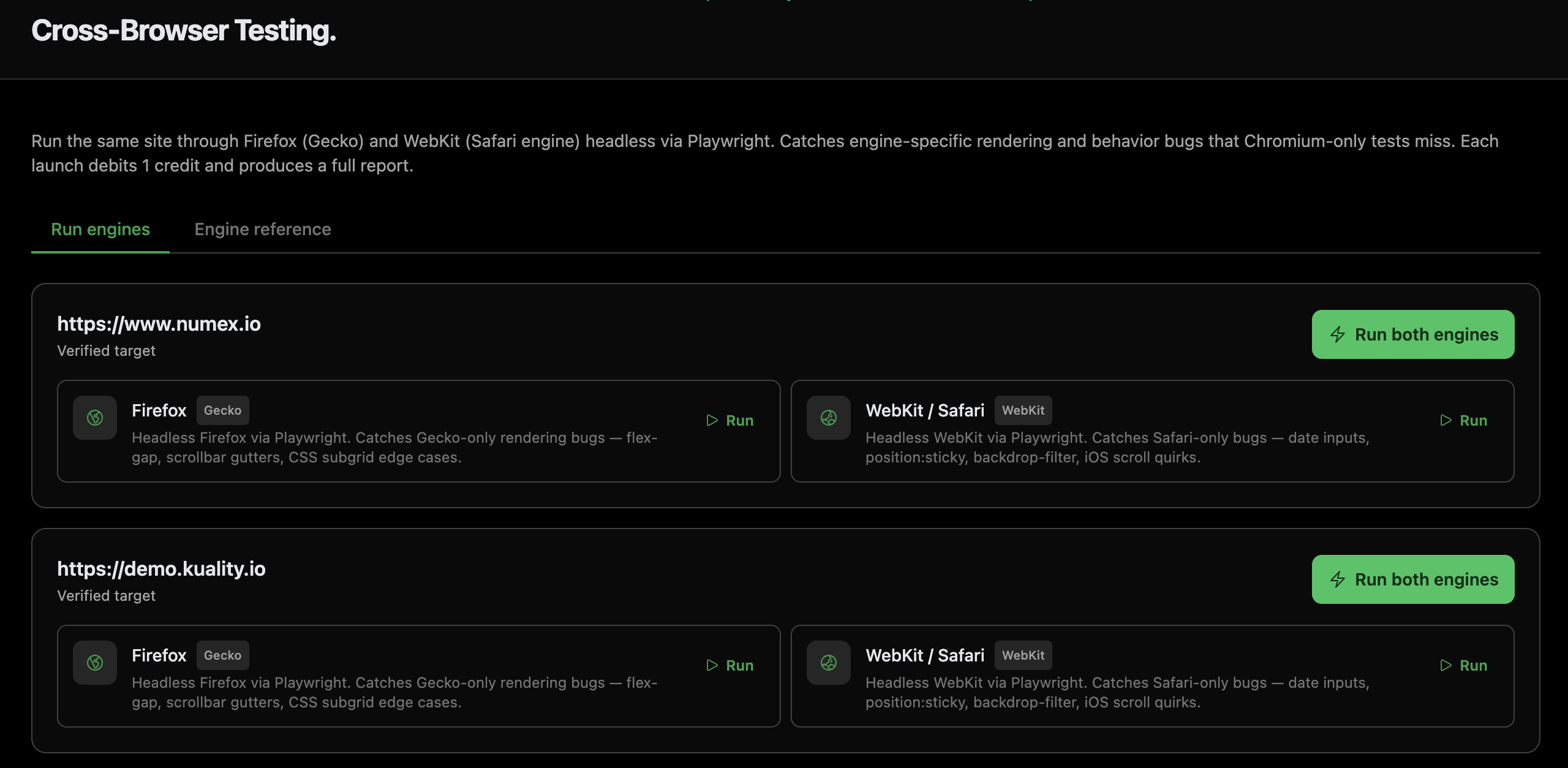
Chromium, Firefox, WebKit. Every commit.
Playwright-powered test runs against all three rendering engines in parallel, plus mobile viewports with real touch emulation. Console errors, network failures, and render-time diffs surfaced per browser so "works in Chrome" stops being a shipping criterion.
- Headless + headful test execution
- Mobile Lighthouse + tap-target audit
- Per-browser console + network logs
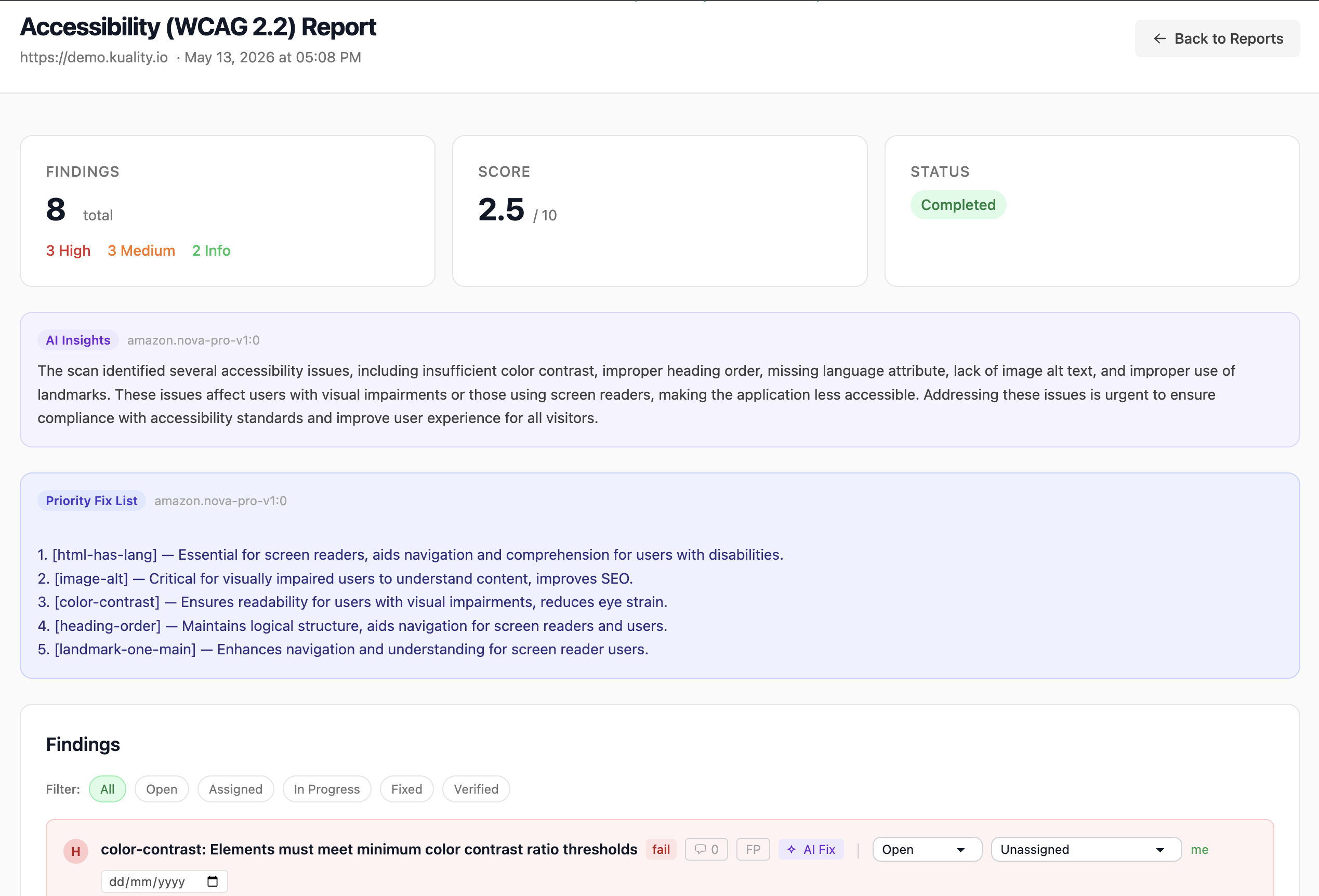
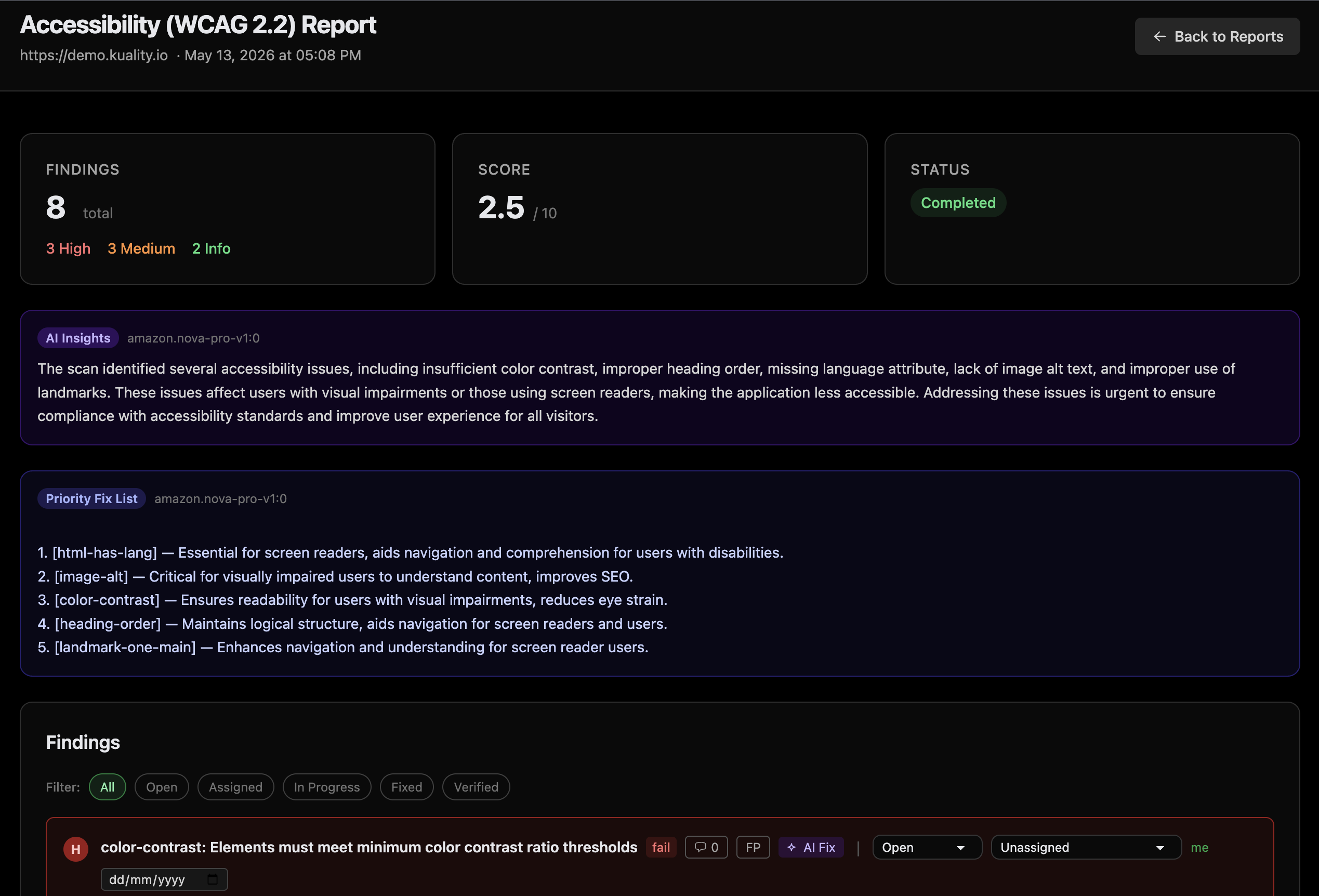
Ship accessible. Stay audit-ready.
axe-core-powered WCAG 2.2 AA audits on every test. Contrast, keyboard nav, ARIA, screen-reader compatibility — with severity grouping, suggested fixes, and an exportable compliance report for your legal team. Stop ADA / EU Accessibility Act lawsuits before they start.
- WCAG 2.1 & 2.2 AA coverage
- Per-component violation grouping
- PDF compliance report for auditors
-
DetailsKuality / AccessibilityPassed · 0 violations
-
DetailsKuality / PerformancePassed · LCP 1.2s
-
DetailsKuality / Security headersPassed · CSP + HSTS
-
DetailsKuality / Visual regressionFailed · 2 pages changed
-
DetailsKuality / Broken linksRunning · 47% complete
Ship only green. Block the rest.
One-line GitHub Action, GitLab step, CircleCI orb, or any curl-ready REST API. Gate every PR on accessibility + performance + visual regression thresholds you define. Results post to the PR as a single status check — no dashboard tab-hopping.
- uses: kuality-io/action@v1
with:
api-key: ${{ secrets.KUALITY_API_KEY }}
url: https://staging.example.com
types: a11y,webvitals,seo
fail-on: high
- Official GitHub Action — verified on the Marketplace
- GitLab / Bitbucket / CircleCI also supported via REST API
- Threshold-based PR blocking + JUnit / JSON output
Run QA like an org. Not a list of test results.
Roles (Owner, Admin, Editor, Viewer), audit logs, SSO/SAML on Pro, and client-portal seats for agencies. One rolled-up Kuality Score per app tracks regressions over time so standups start with data, not opinions.
- RBAC + audit trail
- SSO / SAML (Okta, Auth0, Azure AD)
- Client-facing portals for agencies
Your Next.js app is missing a
Content-Security-Policy
header. Directly exploitable
via the Intercom widget already loaded on /pricing
— an attacker can inject inline script through any reflected XSS vector.
// next.config.js
async headers() {
return [{
source: '/(.*)',
headers: [{
key: 'Content-Security-Policy',
value: "default-src 'self'; script-src 'self' https://widget.intercom.io"
}]
}]
}Every finding, interpreted. Every fix, tailored.
AI reads your findings plus the detected tech stack and explains what matters in plain English. One click generates a code-level fix specific to your framework — different snippet for Next.js, Rails, WordPress, or Nginx. Cached per report so your AI cost stays predictable.
- Findings interpreter, remediation advisor, anomaly narrator
- Risk prioritizer, compliance mapper, test gap advisor
- AI test generator + natural-language test authoring
Every test, smarter.
Not "AI-generated tests" theatre. Real interpretation, prioritization, and remediation built on top of the findings we already produce — tailored to your detected tech stack.
Plain-English context per scan: 'Your Next.js app is missing a CSP header — directly exploitable via the Intercom widget already loaded.'
Per-finding 'AI Fix' button generates a code snippet tailored to your stack — different fix for Next.js vs Rails vs WordPress.
Score dropped 12 points? AI explains why: 'Primary driver: new X-Frame-Options violation, consistent with a CDN config change.'
Re-ranks findings by actual business impact, not CVSS. SQLi in the payment form jumps the queue over an XSS in a read-only blog search.
AI-written 2-3 sentence management summary on the exec PDF — translates findings into business risk language non-technical stakeholders understand.
After tech detection: 'Stripe.js found → run payment flow tests. Auth0 → run RBAC + session. WordPress → prioritize CMS + supply chain scans.'
Auto-maps findings to specific framework controls: GDPR Art. 32, OWASP A05:2021, PCI DSS 6.4.3 — feeds into compliance evidence collection.
Mark a finding as a false positive once; the system pre-flags probable FPs in future scans for your org with a confidence percentage.
AI-powered insights cached per report — your AI cost stays predictable.
36 test types.
One platform, full coverage.
From accessibility to API contract testing to real-device runs — every test type isolated in its own container.
| Check | What it catches | Plan |
|---|---|---|
| Accessibility | WCAG 2.2 AA violations — contrast, labels, keyboard nav, ARIA. | Free |
| Performance | Core Web Vitals, LCP, CLS, INP, bundle size bottlenecks. | Free |
| Broken Links | 4xx/5xx HTTP errors, missing assets, dead redirects. | Free |
| SEO | Meta tags, structured data, sitemap, canonical issues. | Free |
| Security Headers | CSP, HSTS, X-Frame-Options, Referrer-Policy audit. | Free |
| Cross-Browser | Chromium, Firefox, WebKit render + console error diff. | Pro |
| Mobile Friendly | Responsive breakpoints, tap targets, mobile Lighthouse. | Pro |
| Visual Regression | Pixel-diff screenshots against your last known-good build. | Pro |
| Stress Testing | Ramp traffic from your verified domain — find your ceiling. | Pro |
Above is a sample of the 10 most-used checks. The full catalogue:
Free: 10 tests/month on 1 domain · Light ($19/mo): more capacity for small teams · Pro ($79/mo): unlimited, with stress testing, real-device, and AI remediation · Enterprise: custom limits + SSO.